그림과 표를 읽는 멀티모달 RAG
- #AI
- #RAG
- #Multimodal
- #VLM
- #LLM
새로운 AI 기술은 대부분 논문으로 먼저 소개된다. 그래서 최신 흐름을 따라가려면 결국 논문을 보게 되는데, 최근 AI를 공부하며 Attention Is All You Need 같은 유명한 논문을 몇 개 읽어봤다. 그런데 영어인 데다 처음 보는 용어와 수식이 많고, 핵심이 본문이 아니라 그림이나 표에 담겨 있을 때가 많아 한 편을 이해하는 데도 시간이 오래 걸렸다.
이해가 안 되는 부분은 LLM에 물어봤다. 문단을 복사해 붙여 넣고 무슨 뜻인지 되묻는 식이었는데, 그림이나 표는 텍스트가 아니라 물어보기도 애매했다. 논문을 통째로 올리면 그림과 표까지 읽어 쉽게 풀어 주는 도구가 있으면 좋겠다는 생각이 들었다.
마침 이번에 PI Lab Sprint 4를 마쳤는데, 스프린트 주제가 멀티모달 RAG였다. 표·차트·이미지가 섞인 PDF를 읽고 답하는 챗봇을 만들다가, 앞서 논문을 읽으며 느낀 불편이 떠올랐다. 그래서 스프린트에서 배운 걸 이용해, 논문을 쉽게 읽어 주는 챗봇을 직접 구현해 보기로 했다.
이 글에서는 특히 그림과 표를 잘 읽도록 어떻게 구현했는지 정리한다.
프로젝트 소개
이 챗봇은 논문을 읽고 질문한 언어로 답한다. PDF를 직접 올리거나 arXiv에서 키워드로 논문을 검색해 고르면, 그 내용을 설명하거나 궁금한 점에 답해 준다. arXiv는 AI·과학 논문이 주로 올라오는 무료 논문 저장소라, 검색 결과에서 바로 PDF를 가져올 수 있다.
챗봇은 RAG로 동작한다. 논문을 미리 읽어 잘게 쪼개 저장해 두고, 질문이 오면 관련된 부분만 찾아 LLM에게 근거로 넘겨 답하게 한다. 논문 전체를 매번 모델에 넣지 않아도 되고, 찾은 근거로 답하니 덜 지어낸다.
다만 텍스트만으로는 부족하다. 논문의 핵심은 아키텍처 그림이나 결과 표에 들어 있을 때가 많다. "이 그림 설명해줘", "Table 2 결과가 뭐야"까지 답하려면 그림과 표도 읽혀야 한다.
기본 구조
먼저 그림·표는 미뤄두고, 텍스트만 읽는 가장 단순한 RAG 채팅 웹앱부터 만든다. 파이프라인은 인덱싱과 답변, 두 단계로 나뉜다.
- 인덱싱 — 논문을 미리 저장한다.
pypdf로 PDF에서 텍스트를 뽑아 500자씩(앞뒤 50자 겹침) 자르고,text-embedding-3-small로 청크마다 1536차원 벡터를 만들어 로컬 Chroma에 저장한다. - 답변 — 질문이 오면 질문도 임베딩해 가까운 청크 5개를 찾고, 그 청크를 근거로
gpt-4o-mini가 질문한 언어로 답한다.

채팅 화면은 Streamlit, 백엔드 API는 FastAPI, 벡터 검색은 Chroma, 임베딩과 답변 생성은 OpenAI 모델을 쓴다. 프롬프트에 "문서에 없으면 모른다고 답하라"고 지정해 논문에 없는 내용을 지어내지 않게 한다.
여기까지가 기본형이다. 본문에 글로 적힌 개념·기여·요약은 잘 답하지만, 그림이나 표 속 수치는 답하지 못한다. 텍스트만 읽기 때문이다. 여기서부터 그림과 표를 읽히는 게 이 프로젝트의 핵심이다.
평가 방법
그림과 표를 읽히기 전에, 변화를 숫자로 확인할 평가 방법부터 만든다. 그림이나 표를 읽는 기능을 새로 더한 뒤 정말 나아졌는지 감으로만 판단하면, 효과 없는 작업을 효과 있다고 넘기기 쉽다.
Attention 논문에 대한 질문 18개를 만들고, 답이 본문·표·그림 중 어디에 있는지에 따라 각 6개씩 나눈다. 그리고 챗봇의 답을 다른 LLM이 채점하게 한다. 지어내지 않았는지(faithful), 핵심을 담았는지(covers)를 0/1로 매긴다.

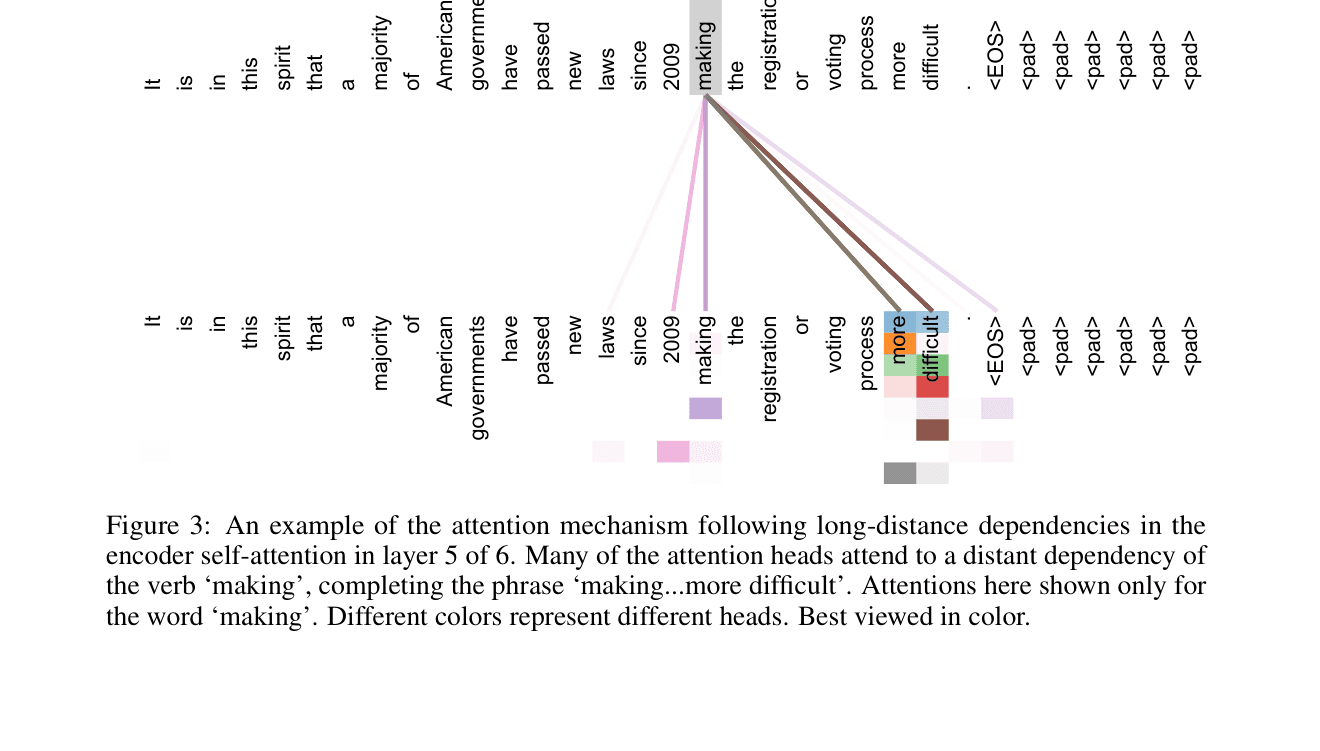
텍스트만 읽는 기본형으로 한 번 돌려 베이스라인을 잡는다. 표 질문의 covers는 67%, 그림 질문은 83%다. 텍스트만 읽는데 그림 질문을 답하는 이유는, 논문 본문이 그림을 글로 설명하기 때문이다("Figure 1은 인코더와 디코더를…"). 이 값을 기준으로 두고, 그림·표를 읽히면 점수가 오르는지 본다.
표 읽기
표부터 손댄다. 계획은 PDF에서 표를 찾아 마크다운 표로 바꿔 텍스트 청크와 같은 공간에 넣는 것이다. 마크다운으로 바꾸면 행과 열 구조가 글자로 남아 LLM이 읽기 좋다.

그런데 pdfplumber의 선(괘선) 기반 검출은 세로줄이 없는 논문 표를 제대로 못 잡고, 오히려 어텐션을 시각화한 그림 페이지를 빈 칸과 한 글자짜리 칸이 가득한 큰 표로 잘못 인식한다. 그래서 행·열 수와 빈 칸 비율로 진짜 표만 남기는 필터를 둔다.
필터를 넣고 평가셋을 다시 돌려도 표 점수(covers 67%)는 그대로다. 이유는 단순하다. 표 속 숫자가 이미 텍스트에 들어 있다. pypdf가 텍스트를 뽑을 때 28.4, 41.8 같은 값을 한 줄로 펴서 가져오기 때문에, 표를 따로 떼어내 마크다운으로 만들어도 검색에 새로 추가되는 정보가 없다.
여기서 확인한 게 있다. 표를 추출하는 것과 그 내용을 답에 반영하는 것은 다르다. 그리고 평가셋이 없으면 이런 헛수고를 효과 있다고 착각하기 쉽다. 그래서 표는 더 욕심내지 않는다. 진짜 표는 마크다운으로 뽑아 넣되 가짜 표만 걸러 내는 선에서 멈춘다. 각 청크에 단 type·page 메타데이터는 뒤에서 쓰는데, type은 검색 종류를 거를 때, page는 출처를 표시할 때다. 멀티모달이 실제로 필요한 곳은 텍스트가 아예 없는 그림이다.
그림 읽기
표는 그래도 글자가 들어 있지만, 그림은 검색할 글자가 없다. 임베딩은 글자를 벡터로 바꾸는 방식이라, 글자가 없으면 검색에 걸리지 않는다.
방법은 그림을 글로 바꾸는 것이다. 이미지를 멀티모달 모델(VLM)에게 보여 캡션을 받아, 그 캡션을 텍스트 청크처럼 같은 공간에 넣는다. 그러면 "이 그림 설명해줘" 같은 질문이 캡션에 검색된다.

그림을 꺼내는 데서 문제가 하나 있다. 논문 그림 대부분이 선과 도형으로 그린 벡터 그래픽이라, 페이지에 박힌 이미지를 뽑는 page.get_images()로는 0개가 나온다. 그래서 페이지에 그려진 벡터 도형 수가 일정 기준을 넘는데 이미지가 없으면, 그 페이지 전체를 한 장의 PNG로 렌더해 VLM에 넘긴다.
평가 신뢰성
그림 캡션을 넣고 평가셋을 돌리는데, 그림 점수가 오르지 않는다. 게다가 같은 논문·같은 인덱스로 두 번 돌렸는데 점수가 83%와 50%로 다르게 나온다. 데이터는 바뀌지 않았다.
기능을 더 손대기 전에 측정 도구부터 점검한다. 원인은 두 가지다. 채점하는 LLM이 같은 답을 매번 다르게 판정했고(출력의 무작위성을 없애도록 temperature를 0으로, seed를 고정해 해결), 답은 한국어인데 정답 키워드를 영어로 적어 둬서 채점이 흔들렸다(의미로 채점하고 키워드 언어를 맞춰 해결).

이 과정에서 얻은 교훈이 꽤 의미있었다. 측정값이 움직이지 않으면, 기능보다 측정 도구를 먼저 점검해야 한다. 평가를 신뢰할 수 없으면 그 위에서 내린 판단도 신뢰할 수 없다.
검색 간섭
측정을 고치고 다시 보면 실제 문제는 따로 있다. 그림 캡션을 넣자 텍스트 질문의 정답률이 83%에서 67%로 떨어진다. 질문마다 가까운 청크 5개를 근거로 쓰는데, 그림 캡션 청크가 상위 5개에 끼면서 필요한 본문 청크가 밀려나기 때문이다.

해결은 질문의 의도를 보고 검색 범위를 좁히는 것이다. 청크를 저장할 때 종류를 type 메타데이터(text·table·figure)로 함께 달아 두고, 질문에 figure·table 같은 말이 있는지로 어떤 종류를 찾을지 정한다. 그림을 묻는 질문에는 그림과 본문만, 표를 묻는 질문에는 표와 본문만 남도록 벡터 검색에 메타데이터 조건을 걸어, 상위 5개를 뽑기 전에 후보를 걸러 낸다.
이 규칙을 넣으면 텍스트 질문은 83%로 돌아오고, 그림을 넣어도 전체 점수가 떨어지지 않는다. 모달을 많이 넣을수록 좋아지는 게 아니라, 잘못 섞으면 서로의 검색을 방해한다.
프롬프트 개선
이제 표·그림·본문이 한 답변의 근거로 함께 들어온다. 그런데 그냥 이어 붙여 주면 무엇이 표고 그림인지, 몇 페이지에서 왔는지 구분되지 않는다. 그래서 근거마다 종류와 페이지를 표시하고([표, p.8], [그림, p.3]), "특정 표·그림·페이지에 근거하면 출처를 밝혀라"는 규칙을 시스템 프롬프트에 더한다.
검색은 그대로 두고 모델이 근거를 읽는 방식만 바꿨는데, 이 변경으로 표 질문 정답률이 67%에서 83%로 오른다.
차트 읽기
앞의 그림 평가에서 멀티모달 효과가 잘 드러나지 않은 건, Attention 논문은 그림 내용을 본문이 이미 설명하기 때문이다. 그림이 본문에 없는 경우, 대표적으로 데이터 차트는 다르다. 막대·선 그래프의 값과 순위는 본문에 없고 그래프를 봐야 안다.
그래서 차트가 있는 다른 논문(Visual Attention Network)으로 평가셋을 만든다. 여러 모델의 정확도를 비교하는 차트(Figure 1)에 대해 "가장 좋은 모델은?", "가장 낮은 모델은?" 같은 질문 6개다. 텍스트만 읽으면 6개 중 1개(17%)만 맞힌다.
처음에는 차트가 있는 페이지를 통째로 렌더해 캡션을 받는다. 17%에서 33%로 오른다. 그런데 페이지 전체를 한 장에 넣으니 차트가 작게 들어가 세부를 놓친다.
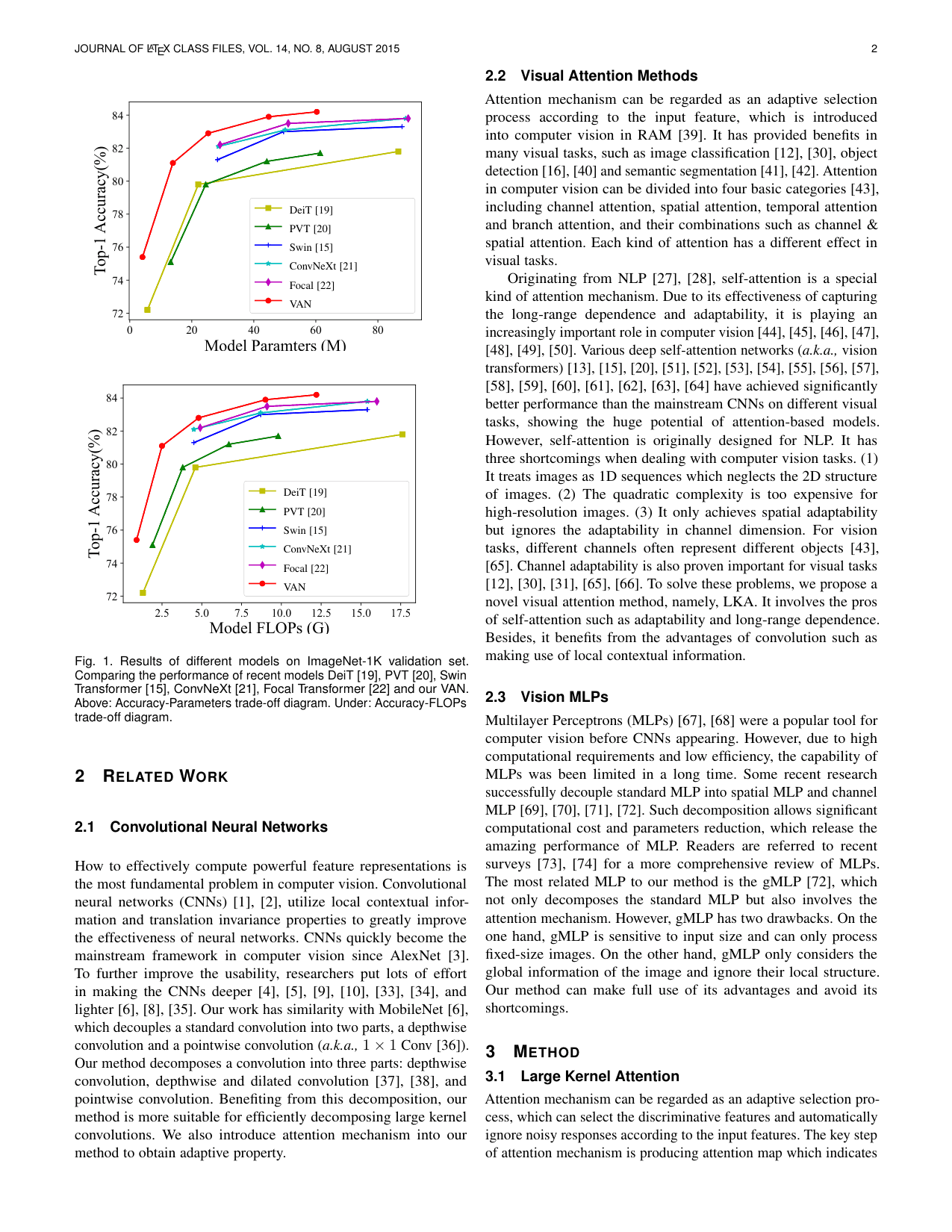
그래서 페이지의 벡터 도형들을 감싸는 사각형(bounding box)을 구해, 그 영역만 잘라 더 크게 렌더한다. 차트가 이미지를 가득 채운다.
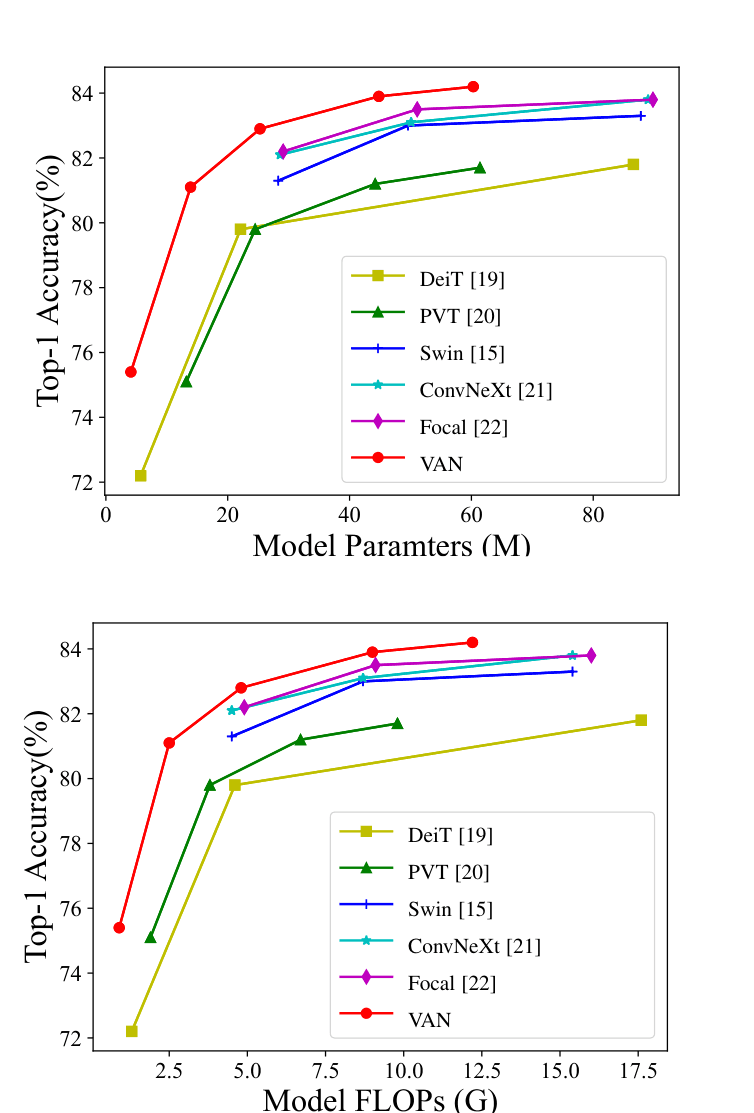
키워드 채점에서는 crop이 33%에서 50%로 오른다. 그런데 그 채점은 답에 정답 모델 이름만 있으면 통과시킨다. 채점을 "정답과 모순 없이 맞혔는가"로 강화하니, crop 점수가 텍스트만 읽을 때 수준으로 다시 떨어진다. 캡션을 열어 보니 모델이 차트를 거꾸로 읽고 있다. 실제로는 VAN이 가장 높은데 "가장 좋은 모델은 DeiT"라고 답한다. 50%는 키워드가 만든 허수였다.
그러면 무엇이 문제인가. RAG와 채점을 빼고 같은 이미지로 캡션만 모델별로 뽑아 본다. gpt-4o-mini는 "최고는 DeiT"(거꾸로), gpt-4o는 "최고는 VAN"(정답)이다. 작은 모델이 이 차트를 못 읽는 것이었다.
모델을 키우면 비용이 걱정이다. 그런데 실제 토큰을 재 보면 다르다. gpt-4o-mini는 이미지를 더 많은 토큰으로 환산하는 구조라 이 이미지 하나에 약 2만5천 토큰을 쓰는 반면, gpt-4o는 약 800 토큰만 쓴다. 그래서 단가는 gpt-4o가 비싸도 캡션 한 번 비용은 거의 같다. 게다가 캡션은 인덱싱 때 한 번만 든다. 그래서 그림 캡션만 gpt-4o로 바꾼다. 캡션이 "VAN이 가장 높고 약 84%"로 정확해지고, 차트 질문 정답이 6개 중 1개에서 4~5개로 오른다.
정리하면, crop은 이미지를 선명하게 했지만 차트를 못 읽던 진짜 원인은 캡션 모델이었다. 그리고 키워드 채점이 없는 개선을 있는 것처럼 보이게 했다. 측정 도구부터 의심하는 게 맞았다.
인덱싱 속도
기능이 늘면서 업로드가 느려진다. 원인은 그림 캡션이다. 그림 여덟 장을 한 장씩 요청하면 그 단계만 17.6초가 걸리는데, 캡션 호출은 서로 독립적이라 동시에 보내면 5.1초로 준다.

다만 동시 요청을 너무 늘리면 rate limit에 걸리니 한도 안으로 제한한다. 그리고 업로드는 작업만 접수하고 처리는 백그라운드에서 진행 상태를 보여줘, 같은 시간이 걸려도 멈춤이 아니라 진행으로 보이게 한다.
마무리
텍스트만 읽던 챗봇에서 시작해 표, 그림, 평가, 검색, 속도를 차례로 다뤘다. 정리하면 이렇다.
- 표를 추출해도 숫자가 이미 본문에 있으면 점수가 오르지 않는다. 추출과 답에 반영하는 것은 다르다.
- 그림은 텍스트가 없어 VLM 캡션으로 글로 바꿔 넣는다. 본문이 그림을 설명하는 논문에선 효과가 잘 안 보이고, 차트처럼 본문에 없는 그림에서 진짜 효과가 난다.
- 차트는 잘라서 크게 보여주는 것만으로는 부족했다. 작은 캡션 모델은 차트를 거꾸로 읽어서, gpt-4o로 키우고서야 제대로 읽었다. 비용은 거의 같았다.
- 캡션을 섞으면 검색이 서로 방해해서, 질문 의도로 검색 범위를 좁혀 해결한다.
매 단계를 작은 평가셋으로 측정한 것이 판단의 기준이 됐다. 측정이 없었으면 효과 없는 작업을 효과 있다고 넘겼을 것이다. 측정 도구 자체가 부정확했던 적도 있었고, 그것을 고치고 나서야 실제 문제가 보였다.
이번이 PI Lab에서의 마지막 스프린트였는데, 가장 재미있었다. 고도화를 페어프로그래밍으로 진행하면서 문제를 어떻게 풀지 서로 의견을 주고받으며 여러 시각에서 볼 수 있었고, 하나씩 고쳐 나가다 결과가 좋아지거나 나빠지면 원인을 따져 보고 부족하면 다시 고민하는 과정이 특히 그랬다. 점수가 오를 때마다 성취감도 있었다.
이번엔 내가 필요한 서비스를 혼자 작게 만들어 봤는데, 표·그림 말고도 더 개선할 부분이 여럿 보였다. 다듬어서 실제로 사람들이 쓸 수 있게 배포까지 해보면 재미있을 것 같다.
이 글은 사실관계나 해석에 오류가 있을 수 있습니다. 잘못된 내용이나 질문이 있으면 댓글로 편하게 남겨 주세요.
Reference
- Attention Is All You Need (2017) — 예제로 쓴 Transformer 원논문
- Visual Attention Network (2022) — 차트 읽기 실험에 쓴 논문